skip to main |
skip to sidebar
Monday, August 10, 2015
Posted by
Corey Harrell
This is a quick post to pass along that I updated my auto_rip script. For those who may not know, auto_rip is a wrapper script for Harlan Carvey's RegRipper program and it executes RegRipper’s plug-ins based on categories and in a specific order. To learn more about my script please see my previous post Unleashing auto_rip. The auto_rip updates are pretty minor. I separated out the changes to a change log instead of documenting changes in the script itself, added a device category (due to a new plug-in), and I added most of the new RegRipper plug-ins Harlan created (as of 7/30/15). The download location can be found on the right of my blog or using this link to its Google drive location.
****** 08/11/2015 Update *******
At this time I removed the compiled executable from auto_rip. The compiled executable is having issues and I'm working to resolve it. However, the perl script is present and works fine. As soon as I'm able to compile the script into an exe then I'll add it back to the auto_rip archive
Tuesday, October 21, 2014
Posted by
Corey Harrell
Organizing is what you do before you do something, so that when you do it, it is not all mixed up.
~ A. A. Milne
"Corey, at times our auditors find fraud and when they do sometimes they need help collecting and analyzing the data on the computers and network. Could you look into this digital forensic thing just in case if something comes up?" This simple request - about seven years ago - is what lead me into the digital forensic and incident response field. One of the biggest challenges I faced was getting a handle on the process one should use. At the time there was a wealth of information about tools and artifacts but there was not as much outlining a process one could use. In hindsight, my approach to the problem was simplistic but very effective. I first documented the examination steps and then organized every artifact and piece of information I learned about beneath the appropriate step. Organizing my process in this manner enabled me to carry it out without getting lost in the data. In this post I'm highlighting how this type of organization is applied to timeline analysis leveraging Plaso.
Examinations Leveraging Categories
Organizing the digital forensic process by documenting the examination steps and organizing artifacts beneath them ensured I didn't get "all mixed up" when working cases. To do examination step "X" examine artifacts A, B, C, and D. Approaching cases this way is a more effective approach. Not only did it prevent jumping around but it helped to minimize overlooking or forgetting about artifacts of interest. Contrast this to a popular cheat sheet at the time I came into the field (links to cryptome). The cheat sheet was a great reference but the listed items are not in an order one can use to complete an examination. What ends up happening is that you jump around the document based on the examination step being completed. This is what tends to happen without any organization. Jumping around in various references depending on what step is being completed. Not an effective method.
Contrast this to the approach I took. Organizing every artifact and piece of information I learned about beneath the appropriate step. I have provided glimpses about this approach in my posts: Obtaining Information about the Operating System and It Is All About Program Execution. The "information about the operating system" post I wrote within the first year of starting this blog. In the post I outlined a few different examination steps and then listed some of the items beneath it. I did a similar post for program execution; beneath this step I listed various program execution artifacts. I was able to write the auto_rip program due to this organization where every registry artifact was organized beneath the appropriate examination step.
Examination Steps + Artifacts = Categories
What exactly are categories? I see them as the following: Examination Steps + Artifacts = Categories. I outlined my examination steps on the jIIr methodology webpage and below are some of the steps listed for system examinations.
* Profile the System
- General Operating System Information
- User Account Information
- Software Information
- Networking Information
- Storage Locations Information
* Examine the Programs Ran on the System
* Examine the Auto-start Locations
* Examine Host Based Logs for Activity of Interest
* Examine Web Browsing
* Examine User Profiles of Interest
- User Account Configuration Information
- User Account General Activity
- User Account Network Activity
- User Account File/Folder Access Activity
- User Account Virtualization Access Activity
* Examine Communications
In a previous post, I said "taking a closer look at the above examination steps it’s easier to see how artifacts can be organized beneath them. Take for example the step Examine the programs ran on the system. Beneath this step you can organize different artifacts such as: application compatibility cache, userassist, and muicache. The same concept applies to every step and artifact." In essence, each examination step becomes a category containing artifacts. In the same post I continued by saying "when you start looking at all the artifacts within a category you get a more accurate picture and avoid overlooking artifacts when processing a case."
This level of organization is how categories can be leveraged during examinations.
Timeline Analysis Leveraging Categories
Organizing the digital forensic process by documenting the examination steps and organizing artifacts is not limited to completing the examination steps or registry analysis. The same approach works for timeline analysis. If I'm looking to build a timeline of a system I don't want everything (aka the kitchen sink approach.) I only want certain types of artifacts that I layer together into a timeline.
To illustrate let's use a system infected with commodity malware. The last thing I want to do is to create a supertimeline using the kitchen sink approach. First, it takes way too long to generate (I'd rather start analyzing than waiting.) Second, the end result has a ton of data that is really not needed. The better route is to select the categories of artifacts I want such as: file system metadata, program execution, browser history, and windows event logs. Approaching timelines in this manner makes them faster to create and easier to analyze.
The way I created timelines in this manner was not efficient as I wanted it to be. Basically, I looked at the timeline tools I used and what artifacts they supported. Then I organized the supported artifacts beneath the examination steps to make them into categories. When I created a timeline I would use different tools to parse the categorized artifacts I wanted and then combine the output into a single timeline in the same format. It sounds like a lot but it didn't take that long to create it. Hell, it was even a lot faster than doing the kitchen sink approach.
This is where Plaso comes into the picture by making things a lot easier to leverage categories in timeline analysis.
Plasm
Plaso is a collection of timeline analysis tools; one of which is plasm. Plasm is capable of "tagging events inside the plaso storage file." Translation: plasm organizes the artifacts into categories by tagging the event in the plaso storage file. At the time of this post the tagging occurs after the timeline data has already been parsed (as opposed to specifying the categories and only parsing those during timeline generation.) The plasm user guide webpage provides a wealth of information about the tool and how to use it. I won't rehash the basics since I couldn't do justice to what is already written. Instead I'll jump right in to how plasm makes leveraging categories in timeline analysis easier.
The plasm switch " --tagfile" enables a tag file to be used to define the events to tag. Plaso provides an example tag file named tag_windows.txt. This is the feature in Plaso that makes it easier to leverage categories in timeline analysis. The artifacts supported by Plaso are organized beneath the examination steps in the tag file. The image below is a portion of the tag_jiir.txt tag file I created showing the organization:
tag_jiir.txt is still a work in progress. As can be seen in the above image, the Plaso supported artifacts are organize beneath the " Examine the Programs Ran on the System" (program execution) and " Examine the Auto-start Locations" (autostarts info) examination steps. The rest of the tag file is not shown but the same organization was completed for the remaining examination steps. After the tag_jiir.txt tag file is applied to plaso storage file then timelines can be created only containing the artifacts within select categories.
Plasm in Action
It's easier to see plasm in action in order to fully explore how it helps with using categories in timeline analysis. The test system for this demonstration is one found laying around on my portable drive; it might be new material or something I previously blogged about. For demonstration purposes I'm running log2timeline against a forensic image instead of a mounted drive. Log2timeline works against a mounted drive but the timeline will lack creation dates (and at the time of this post there is not a way to bring in $MFT data into log2timeline.)
The first step is taking a quick look at the system for any indications that the system may be compromised. When triaging for potential malware infected system the activity in the program execution artifacts excel and the prefetch files revealed a suspicious file as shown below.
The file stands out for a few reasons. It's a program executing from a temp folder inside a user profile. The file handle to the zone.identifier file indicates the file came from the Internet. Lastly, the program last ran on 1/16/14 12:32:14 UTC.
Now we move on to creating the timeline with the command below (the -o switch specifies the partition I want to parse.) FYI, the command below creates a kitchen sink timeline with everything being parsed. To avoid the kitchen sink use plaso filters. Creating my filter is on my to-do list after I complete the tag_jiir.txt file.
log2timeline.exe -o 2048 C:\Atad\test-data\test.dump C:\Atad\test-data\test.E01
The image below shows the "information that have been collected and stored inside the storage container." The Plaso tool pinfo was used to show this information.
Now it is time to see plasm in action by tagging the events in the storage container. The command below shows how to do this using my tag_jiir.txt file.
plasm.exe tag --tagfile=C:\Atad\test-data\tag_jiir.txt C:\Atad\test-data\test.dump
The storage container information now shows the tagged events as shown below. Notice how the events are actually the categories for my examination steps (keep in mind some categories are not present due to the image not containing the artifacts.)
Now a timeline can be exported from the storage container based on the categories I want. The program execution indicator revealed there may be malware and it came from the internet. The categories I would want for a quick look are the following:
- Filesystem: to see what files were created and/or modified
- Web browsing: to correlate web browsing activity with malware
- Program execution: to see what programs executed (includes files such as prefetch as well as specific event logs
The command below creates my timeline based on the categories I want (-o switch outputs in l2tcsv format, -w switch outputs to a file, and filter uses the tag contains.) FYI, a timeslice was not used since I wanted to focus on the tagging capability.
psort.exe -o L2tcsv -w C:\Atad\test-data\test-timeline.csv C:\Atad\test-data\test.dump "tag contains 'Program Execution' or tag contains 'Filesystem Info' or tag contains 'Web Browsing Info'"
The image below shows the portion of the timeline around the time of interest, which was 1/16/14 12:32:14 UTC. The timeline shows the lab user account accessing their Yahoo web email then a file named invoice.83842.zip being downloaded from the internet. The user then proceeded to execute the archive's contents by clicking the invoice.83842.exe executable. This infection vector is clear as day since the timeline does not contain a lot of un-needed data.
Conclusion
Plaso's tagging capabilities makes things easier to leverage categories in timeline analysis. By producing a timeline containing only the categories one wants in order to view the timeline data for select artifacts. This type of organization helps minimize getting "all mixed up" when conducting timeline analysis by getting lost in the data.
Plaso is great and the tagging feature rocks but as I mentioned before I used a combination of tools to create timelines. Not every tool has the capabilities I need so combining them provides better results. In past I had excellent results leveraging the Perl log2timeline and Regripper to create timelines. At this point the tools are not compatible. Plaso doesn't have a TLN parser (can't read RegRipper's TLN plug-ins) and RegRipper only outputs to TLN. Based on Harlan's upcoming presentation my statement may not be valid for long.
In the end, leveraging categories in timeline analysis is very powerful. This train of thought is not unique to me. Others (who happen to be tool developers) are looking into this as well. Kristinn is as you can see in Plaso's support for tagging and Harlan wrote about this in his latest Windows forensic book.
Side note: the purpose of this post was to highlight Plaso's tagging capability. However, for the best results the filtering capability should be used to reduce what items get parsed in the first place. The kitchen sink approach just takes way too long; why wait when you can analyze.
Tuesday, February 11, 2014
Posted by
Corey Harrell
It's been awhile but here is another Linkz edition. In this edition I'm sharing information about the various tools I came across over the past few months.
Process Explorer with VirusTotal Integration
By far the most useful tool released this year is the updated Process Explorer program since it now checks running processes against VirusTotal. This added feature makes it very easy to spot malicious programs and should be a welcome toolset addition to those who are constantly battling malware. To turn on the functionality all you need to do is to select the "Check Virustotal" option from the Options menu.
After it is selected then the new Virustotal column appears showing the results as shown below:
The hyperlinks in the VirusTotal results can be clicked, which brings you to the VirusTotal report. The new functionality is really cool and I can see it making life easier for those who don't have DFIR skills to find malware such as IT folks. Hence, my comment about this being the most useful tool released. The one thing I should warn others about is to think very hard before enabling is the "Submit Unknown Executables" to VirusTotal since this will result in files being uploaded to Virustotal (and thus available for others to download).
Making Static Analysis Easier
I recently became aware about this tool from people tweeting about. PEStudio "is a tool that can be used to perform the static investigation of any Windows executable binary." It quickly parses an executable file presenting you with indicators, VirusTotal results, imports, exports, strings, and a whole lot more as shown below.
Automating Researching URLs, Domains, and IPs
The next tool up to bat automates researching domains, IPs, hashes, and URLs. It's a pretty slick tool and I can see it being an asset when you need to get information quickly. TekDefense describes Automater as "a URL/Domain, IP Address, and Md5 Hash OSINT tool aimed at making the analysis process easier for intrusion Analysts." If you are tasked with doing this type of analysis then you will definitely want to check out this tool. The screenshot below is part of the report generated for the MD5 hash ae2fc0c593fd98562f0425a06c164920; the hash was easily obtained from PEStudio.
Norben - Portable Dynamic Analysis Tool
The next tool makes the dynamic analysis process a little easier. "Noriben is a Python-based script that works in conjunction with Sysinternals Procmon to automatically collect, analyze, and report on runtime indicators of malware. In a nutshell, it allows you to run your malware, hit a keypress, and get a simple text report of the sample's activities." To see this tool in action you can check out Brian Baskin's post Malware with No Strings Attached - Dynamic Analysis; it's an excellent read. In order to get a screenshot, I ran the previous sample inside a virtual machine with Noriben running.
I'm Cuckoo for Cocoa Puffs
You can probably guess what my kids ate for breakfast but this next tool is not child's play. Version 1 of the Cuckoo Sandbox has been released. The download is available on their download page. For those who don't want to set up their own in-house sandbox then you can use Malwr (the online version).
Pinpointing
The next tool comes courtesy of Kahu Security. The best way to explain the tool is to use the author's own words from his post Pinpoint Tool Released.
"There are many times where I come across a drive-by download, especially malvertisements, and it takes me awhile to figure out which file on the compromised website is infected. I wrote Pinpoint to help me find the malicious objects faster so I can provide that info to webmasters for clean-up purposes."
The post provides some examples on the tool's use as well as their most recent post Pinpointing Malicious Redirects (nice read by the way.) You can grab the tool from the tools page.
What You See May Not Be What You Should Get
I thought I'd share a post highlighting shortcomings in our tools while I'm on the topic about malware. Harlan posted his write-up Using Unicode to hide malware within the file system and it is a well written post. The post discusses an encounter with a system impacted by malware and the anti-forensic techniques used to better hide on the system. One method used was to set the file attributes to hidden and system; to hide a folder from the default view settings. The second method and more interesting of the two use the use of Unicode in the file name path. What the post really highlighted was how multiple tools - tools that are typically in the DFIR toolset - do not show the Unicode in the file path. This would make it possible for anyone looking at a system to overlook the directory and possibly miss an important piece of information. This is something to definitely be aware about for the tools we use to process our cases.
Do You Know Where You Are? You're In The NTFS Jungle Baby
If you haven't visited Joakim Schicht's MFT2CSV website lately then you may have missed the tools he updated on his downloads page. The tools include: LogFileParser that parses the logfile (only open source logfile parser available), mft2csv that parses the $MFT file, and UsnJrnl2Csv that parses the Windows Change Journal. The next time you find yourself in the NTFS jungle you may want to visit the mft2csv site to help you find your way out.
Still Lost in the NTFS Jungle
Rounding out this linkz post are a collection of tools from Willi Ballenthin. Willi had previously released tools such as his INDX parser and python-registry. Over the past few months he has released some more NTFS tools. These include: list-mft to timeline NTFS metadata, get-file-info to inspect $MFT records, and fuse-mft to mount an $MFT. I haven't had the time to test out these tools yet but it's at the top of my list.
Thursday, September 12, 2013
Posted by
Corey Harrell
Sometime ago I released my Tr3Secure
Volatile Data Collection Script which is a dual purpose triage script. The
script can not only be leveraged “to properly preserve and acquire data from
live systems” but it can also help to train people on examining volatile data. I
have completely overhauled the Tr3Secure collection script including collecting
non-volatile data. I wanted to release the updated script to the community but
I encountered a small issue.
At the time my updated script was collecting locked files
using HBGary’s FGET tool. FGET is a handy little tool. It can collect locked files
such as registry hives both locally and remotely. It can natively collect a
collection of files such as the registry hives or it can collect any file or
NTFS artifact specified by file path. The best part about FGET was the ability
to use it in scripts. FGET was freely available that at first was downloadable
from the HBGary website then downloadable from the registered users’ portion of
the HBGary website. Unfortunately, FGET is no longer available for download and
this was my small issue. How could I release a script that depended on a tool
no longer available? I can’t so I set out to find a FGET replacement so I can
have ability to collect locked files and NTFS artifacts while also scripting
with it in a Windows batch file. This
post outlines the items I came across as I searched for my replacement.
Invoke-NinjaCopy
The first item up came from a recommendation by Jon Turner (@z4ns4tsu). Invoke-NinjaCopy
is a powershell script that according to its Github home “copies a file from an
NTFS partitioned volume by reading the raw volume and parsing the NTFS
structures. This bypasses file DACL's, read handle locks, and SACL's”. The clymb3r blog post Using
PowerShell to Copy NTDS.dit / Registry Hives, Bypass SACL’s / DACL’s / File
Locks explains why the author created the script and demonstrates how they
were able to grab the NTDS.dit (aka Active Directory) off a live system. Out of
everything I came across Invoke-NinjaCopy was the only script/tool capable of
grabbing locked files either locally or remotely like FGET can. Towards the top
of my to-do list is to take a closer look at Invoke-NinjaCopy since I think it
could be helpful in incident response activities in addition to pen testing.
RawCopy
Lately it seems like if I need anything related to the NTFS
file system I first check Joakim Schicht’s mft2csv’s website. Joakin’s site
is a gold mine and anyone doing forensics on the NTFS file system should become
familiar with his site. One of his available tools is RawCopy which is an “application that copy
files off NTFS volumes by using low level disk reading method”. RawCopy can
copy out either the data ($DATA) or all attributes from the file’s MFT entry. It
can copy files using either the file path or MFT record number. Download RawCopy from
here.
TZWorks NTFSCopy
Next up is a tool from the folks over at TZWorks called
NTFSCopy. NTFSCopy is a “tool that can copy
any file (or alternate data stream) from a NTFS file system. This can be from
either from a live system or from an imaged NTFS volume or drive”. Similar
to the other items, the tool is able to bypass locks and permissions to grab
files and it can copy NTFS artifacts. To copy a file you can specify the file
name, cluster, or MFT record number. NTFSCopy does work as described and quickly
can copy NTFS artifacts and locked files from live systems. For anyone wanting
to copy files from a live system should take a close look at NTFSCopy (downloaded the tool from here).
Just keep in mind the free version is for non-commercial use only but there is
a commercial version available.
ircollect
The next tool up is a Python script developed by David
Kovar. ircollect “is a Python tool
designed to collect files of interest in an incident response investigation or
triage effort”. David’s blog post IRcollect
– collect incident response information via raw disk reads and $MFT parsing
provides additional information about the script. I think this is an
interesting project since everything is done using Python and it’s one I’m
going to keep my eye on.
OSTriage
The last item may be overkill as a FGET replacement since it
is a complete triage tool. Eric Zimmerman’s OSTriage is still in development
and I was afforded the opportunity to test it. The tool is able to parse
artifacts and presents a range of information. Some of the presented information
includes: P2P, network information (ARP cache and open ports), basic
system information, browser history, browser searches, and USB devices. OSTriage
even has the capability to image RAM. This is a tool to be on the look for.
For those wondering what I ended up deciding to replace FGET
with will have to wait until my next post when I release the new and improved TR3Secure collection script.
Thursday, February 14, 2013
Posted by
Corey Harrell
The Linkz for various tools have been piling up in the hopper. For some too much time has passed and others have already done an adequate job talking about them. In this long overdue Linkz post I’m trying to touch on a few links and tools people may not be too familiar with. Just read the headings to get a feel for if any of the linkz apply to the work you do.
Custom Googles
Google has been one of my most reliable tools over the years. The answer to any question is only a few keyboard clicks away. Google is even better with the ability to create a custom Google that only searches specific sites. It seems as if these custom Googles have been my go to tool lately; so much so that I want to share them with others.
If you need to find anything related to digital forensics and incident response then the Digital Forensic Search is the one you will want. If you need to research a piece of malware then check out the Malware Analysis Search. Mila over at Contagio Malware Dump put together a nice post containing links to custom Googles. One of the links was for Malware Sample Search which is handy for the times you are looking for a specific piece of malware. If you need to research a vulnerability or exploit then the Vulnerability Search should be one of your first stops.
Links to Useful Public Resources
I picked up on this site some time ago. The Roberto Perdisci website has a page outlining useful public resources. The links cover: networking and network security, network traffic datasets, malware collection and analysis, pen testing / exploits/ forensics, machine learning, and program analysis. The page has a ton of gems listed so it’s worth taking some time to go through them.
I sent a few links out to Twitter in response to a question and they pertain to useful public resources. The public resources are malware repositories and these links outline the various repositories available. The first link is Lenny Zeltser's Malware Sample Sources for Researchers while the second is Mila's Links and resources for malware samples.
Malware Downloaders and Scappers
These next round of links are all on my list to test; they all look outstanding and should be a nice addition to my tool kit.
At times there is a need to download malware from a website, or two, or 50. In these situations trying to do this manually might not be the best option. This is where the next few links come into play. The first tool has been around for some time but it’s new to me. XyliBox posted his Malware Auto-downloader v1.7 a few years back. The next malware downloader looks like an outstanding tool to continuous download malware from known malicious websites. Kyle Maxwell occasionally tweeted about a project he was working on so when he released it I was really looking forward to reading about it. He extended the mwcrawler (another downloader) into a tool he refers to as Maltrieve. To fully see what he did check out his post Maltrieve: retrieving malware for research and grab the tool from Maltrieve on Github.
The last link is for a malware scrapper. Jamie Levy released her getmalwaredomains Python script. It seems like a nifty little script since it “collects domain/IP/Date/Reverse Lookup information from malwaredomainlist.com”.
IDX Information and Parsers
Java exploits have been a topic I frequently discussed. Not only because it seems like every few months there is a new zero-day but because I keep encountering it on my examinations such as in the post Finding the Initial Infection Vector. One artifact from Java exploits and Java malware occurs when they get downloaded into the Java cache. An index file (IDX) is created and it contains a wealth of information. I briefly touched on IDX files in the post (Almost) Cooked Up Some Java. The little research I did does not even compare to what others have done. First Brian Baskin released his Java Cache IDX Parser. Then Harlan did a few blog posts about IDX files (one of them was Bin Mode: Parsing Java *idx files). In one of Harlan’s posts he pointed out that Joachim Metz was sharing information about the IDX file format on the ForensicsWiki Java page. Mark Woan released his Java IDX Format Specification document where he breaks down the file format for different IDX file versions in addition to his JavaIDX parser. Rounding out the IDX parsers Harlan released his IDXparse script. Java exploits and Java malware are only going to get worse so if you aren’t familiar with IDX files then it might be time to get acquainted.
Memory Forensics
Last Fall there was a new memory imager on the block called pmem. The Scudette in Wonderland blog did a nice write-up about pmem in the post The PMEM Memory acquisition suite. The pmem tool itself can be downloaded from the Volatility Google page. Speaking about Volatility. I am truly impressed with the amount of documentation they have in their Wiki. If you use Volatility or want to learn about the tool then you should definitely check out their Wiki. For example, check out the Volatility 2.2 Release Notes page and then check out their command reference for the: Windows Core, Windows GUI, Windows Malware, and Windows registry. Finally, browse through the rest of the Wiki because I only mentioned some of it. Again, really impressive.
NirLauncher
This nice tool is pretty slick. I use the tools from Nirsoft and Sysinternals for different purposes. I like the tools so it didn't bother me too much having to launch multiple stand-alone executables. I'm not sure how I missed this but one I'm glad the NWC3 training I sat through last fall opened my eyes. Nirsoft has a tool called Nirlauncher. Nirlauncher is a single interface that can be used to run "more than 150 portable freeware utilities". Check out the screenshot below:
It gets even better. There is a package for the Sysinternals tools as well.
Like I said, pretty slick. Nirlauncher can be downloaded from here and the Sysinternals tools can be grabbed from here.
PE Executables
Again these next two links are on my list to test. First up HiddenIllusion released his tool AnalyzePE. In his own words it " wraps around various tools and provides some additional checks/information to produce a centralized report of a PE file". It seems like the tool is a good way to automate some PE analysis tasks. The last link is for the tool PE_Carver which " carves EXEs from given data files, using intelligent carving based upon PE headers". This might be a handy little utility and save time from having to manually carve out PE files with a hex editor.
Monday, October 8, 2012
Posted by
Corey Harrell
There is a tendency to focus on what is different when we are faced with newer operating systems. What are the security changes and how does that impact security testing against it? What are the new artifacts and what new information do they provide? The focus is mostly on the changes as it relates to us looking at the operating system. However, there are other changes that may impact us even more and the way we do our jobs. These changes occur when we use these newer operating systems on the workstations we use for analysis and the changes impact how our tools operate. The User Account Control feature in the newer operating systems is one such change impacting how we use our tools.
User Account Control (UAC) was first introduced with Windows Vista and the feature carried over to Windows 7. By default, UAC is turned on in both operating systems. “The primary goal of User Account Control is to reduce the exposure and attack surface of the Windows 7 operating system by requiring that all users run in standard user mode, and by limiting administrator-level access to authorized processes.” This means even if a user account is in the administrators group every application the account runs will only have standard user privileges instead of the all powerful administrative privileges. In essence, we are not administrators when UAC is turned on.
It’s fairly easy to see the impact UAC has on a user account with administrative privileges. With UAC turned on, open a command prompt and type the command “whoami.exe /priv” to see the privileges of the logged on user account (if your system has UnxUtils configured in your path then make sure to run Windows\System32\whoami.exe).
C:\> whoami.exe /priv
As shown above the user account only has five privileges and none of them are the elevated privileges typically associated with administrator accounts. The two ways to get around UAC is to either turn it off or to use the “Run As” feature when starting an application. Continuing to see the impact of UAC, with the same user account re-run the command “whoami.exe/ priv” with either UAC completely turned off or with a command prompt opened with the “Run As” feature. Notice the difference in the privileges the user account has as shown below.
C:\> whoami.exe /priv
UAC Impact on Digital Forensic and Incident Response Tools
UAC will impact any application that requires administrative privileges to function properly. I first encountered the impact UAC has on applications is when I was working on a script to examine volume shadow copies. My script needed elevated privileges to work and without it the script would just fail. Why the sudden interest in UAC now? Last week a new DFIR program was released and the tool requires elevated privileges to run properly. A few people encountered an error when running the program on both Windows Vista and Windows 7. The program in question is Harlan’s Forensic Scanner and the error some people saw when clicking the Init button is below.

The error is a direct result of UAC being enabled on the workstations running the Forensic Scanner. To get around UAC and thus the error, all one has to do is use the “Run As” feature when launching the Forensic Scanner (or in my case by disabling UAC completely). Again, the UAC error is not unique to the Forensic Scanner; it’s any program that requires administrative privileges. With that said let’s take a closer look at what is really occurring with the scanner and UAC.
I monitored the Forensic Scanner as it executed with ProcessMonitor using an administrative user account with UAC turned on. The screenshot below shows the first permission issue encountered due to the restricted privileges imposed by UAC.
The event shows access is being denied when the scanner tries to open the M:\Windows\system32\config\software hive in my mounted forensic image. Now let’s take a look at the same event with UAC turned off (or with the scanner being executed with the “Run As” feature).
The event shows the result is now a success instead of the denied access previously encountered. The end result is the software registry hive was opened. Now the error some people are encountering makes a little more sense: “No filename specified at PERL2EXE_STORAGE/WinSetup.pm line 136”. The Forensic Scanner is unable to open the registry hives because the user account being used has standard privileges since UAC removed the administrative privileges.
When we upgrade our workstations to newer operating systems it may impact the way our tools work. The User Account Control feature introduced with Windows Vista and carried over to Windows 7 is just one example. When the User Account Control feature is turned on any tools needing administrative privileges will no longer function properly.
Thursday, October 4, 2012
Posted by
Corey Harrell
It looks like Santa put his developers to work so they could deliver an early Christmas for those wanting DFIR goodies. Day after day this week there was either a new tool being released or an updated version of an existing tool. In this Linkz edition there isn’t much commentary about the tools because I’m still working my way through testing them all to better understand: what the tool is, how the tool functions, and if the tool can benefit my DFIR process. Without further ado here are the Linkz of the DFIR goodies dropped in the past week.
Big shout out to Glen (twitter handle @hiddenillusion) for his steady stream of tweets from the 2012 Open Source Digital Forensics Conference saying what the new tool releases were.
RegRipper Plugins
The RegRipper project released a new archive containing a bunch of plugins. The plugins extract a wealth of information including: program execution artifacts (appcompatcache, direct, prefetch, and tracing), user account file access artifacts (shellbags), and a slew of plugins to create timeline data (appcompatcache_tln, applets_tln, networklist_tln, and userassist_tln). For the full detail about what was updated check out Wiki History page and to get the new archive go to the download section on the RegRipperPlugins Google code site.
ForensicScanner
While on the topic about a tool authored by Harlan, I might as well talk about his latest creation. Harlan released a new tool named Forensic Scanner followed by a detailed post explaining what the tool is. To get a better understanding about how to use the scanner there’s documentation on the Wiki page for ScannerUsage (there's also a user guide included in the zip file). What I find really cool about this tool is how it will speed up examinations. All one has to do is point the Forensic Scanner at a mounted image and then it extracts all information fairly quick. It reduces the time needed for extracting information so an analysis can start sooner; thus reducing the overall examination time. The tool is hosted on the download section of the ForensicScanner Google code site.
Volatility
Up next is another tool that is plugin based but this time around I’m pretty speechless. All I can say is the project has released a ton of information to accompany its latest version. Leading up to the release the project released a new plugin every day for a month and each plugin was accompanied with a blog post. Jamie Levy did an outstanding job summarizing all the blog posts: Week 1 of the Month of Volatility Plugins posted, Week 2 of the Month of Volatility Plugins posted, and Week 3 of the Month of Volatility Plugins posted. To grab the latest Volatility version go to the Google code site download section and to see what is new check out the Volatility 2.2 release notes.
Log2timeline
Another great tool has been updated but this time it’s a tool for performing timeline analysis. Log2timeline 0.65 was released a few weeks ago; I know this post is discussing tools released in the last week but I can’t do a toolz post and completely ignore L2T. One cool update is the addition of a new input module to parse utmp file which is an artifact on Linux that keeps track of user logins and logouts on the system. To grab Log2timeline 0.65 go to the Google code site download section and to see all the updates check out the Changelog.
L2T_Review
There are different ways to review the Log2timeline output data depending on the output’s format. Typically, people use the csv output and in this case a few different options were available. The csv file could be Grepped, viewed in a text editor, or examined with a spreadsheet program such as Microsoft Excel (refer to jIIr post Reviewing Timelines with Excel) or OpenOffice Calc (refer to jIIr post Reviewing Timelines with Calc). Now there’s another option and it’s a pretty good option at that. David Nides has been working on his L2T_review tool for reviewing log2timeline csv timelines. He posted about it a few times including here, here, and here. Typically, I don’t mention tools still in beta but I wanted to make an exception for this one. I finally got around to testing L2T_review this week and I definitely liked what I saw.
Sleuth Kit and Autopsy
The 2012 Open Source Digital Forensics Conference did occur this week so it shouldn’t be a surprise to see a new version of the Sleuth Kit released. I haven’t had the time to test out Sleuth Kit 4.0 nor have I been able to look into what the new updates are. Sleuthkit 4.0 can be downloaded from the Sleuth Kit website and the History page can be referenced to see what the updates are. The Autopsy Forensic Browser is a graphical interface to The Sleuth Kit and a new Windows beta version was released last month. I quickly tested out the functionality and I’m truly impressed. I’ve been looking for a decent free forensic browser besides FTK Imager to run on Windows and now I can say my search is over. Autopsy is that forensic browser and it can be downloaded from the Autopsy download page.
HexDive
I’ve mentioned the HexDive program on my blog a few times and the latest is when I was analyzing a keylogger. HexDive has been updated so it provides more context and testing out this new functionality is on my weekend to-do list.
ProcDOT
Speaking about malware analysis. I picked up on this next tool from a Lenny Zeltser tweet. ProDOT is “tool processes Sysinternals Process Monitor (Procmon) logfiles and PCAP-logs (Windump, Tcpdump) to generate a graph via the GraphViz suite”. This tool seems really cool by being able to correlate the ProcMon logfile with a packet capture to show how the activity looks. Yup, when I’m running HexDrive against a malware sample the follow up test will be to launch the malware and then see how the dynamic information looks with ProcDOT.
GRR Rapid Response
I first learned about GRR when I attended the SAN Digital Forensic and Incident Response summit last June. GRR Rapid Response is an incident response framework that can be used when responding to incidents. At the top of my to-do list when I have a decent amount of free time will be set up GRR in a lab environment to get a better understanding how the framework can benefit the IR process. The GRR homepage provides some overview information, the Wiki page provides a wealth of information, and the GRR Rapid Response - OSFC 2012.pdf slide deck contains information as well. GRR itself can be found on the download page.
Lightgrep is open source!
LightGrep is a tool to help perform fast searches. I have yet to try this software out but an interesting development is the core Lightgrep engine is now open source. This will be one to keep an eye on to see how it develops.
bulk_extractor
Rounding out this edition of Linkz for Toolz is a new version for the program bulk_extractor. Bulk_extractor scans a disk image, a file, or a directory of files and extracts useful information without parsing the file system or file system structures. Again, this is another tool on my to-do list to learn more about since my free time has been spent on improving my own processes using the tools already in my toolkit.
Wednesday, August 15, 2012
Posted by
Corey Harrell
In this Linkz edition I’m mentioning write-ups discussing tools. A range of items are covered from the registry to malware to jump lists to timelines to processes.
RegRipper Updates
Harlan has been pretty busy updating RegRipper. First RegRipper version 2.5 was released then there were some changes to where Regripper is hosted along with some nice new plugins. Check out Harlan’s posts for all the information. I wanted to touch on a few of the updates though. The updates to Regripper included the ability to run directly against volume shadow copies and parse big data. The significance to parsing big data is apparent in his new plugin that parses the shim cache which is an awesome artifact (link up next). Another excellent addition to RegRipper is the shellbags plugin since it parses Windows 7 shell bags. Harlan’s latest post Shellbags Analysis highlights the forensic significance to shell bags and why one may want to look at the information they contain. I think these are awesome updates; now one tool can be used to parse registry data when it used to take three separate tools. Not to be left out the community has been submitting some plugins as well. To only mention a few Hal Pomeranz provided some plugins to extract Putty and WinSCP information and Elizabeth Schweinsberg added plugins to parse different Run keys. The latest RR plugin download has the plugins submitted by the community. Seriously, if you use RegRipper and haven’t checked out any of these updates then what are you waiting for?
Shim Cache
Mandiant’s post Leveraging the Application Compatibility Cache in Forensic Investigations explained the forensic significance of the Windows Application Compatibility Database. Furthermore, Mandiant released the Shim Cache Parser script to parse the appcompatcache registry key in the System hive. The post, script, and information Mandiant released speaks for itself. Plain and simple, it rocks. So far the shim cache has been valuable for me on fraud and malware cases. Case in point, at times when working malware cases programs execute on a system but the usual program execution artifacts (such as prefetch files) doesn’t show it. I see this pretty frequently with downloaders which are programs whose sole purpose is to download and execute additional malware. The usual program execution artifacts may not show the program running but the shim cache was a gold mine. Not only did it reflect the downloaders executing but the information provided more context to the activity I saw in my timelines. What’s even cooler than the shim cache? Well there are now two different programs that can extract the information from the registry.
Searching Virus Total
Continuing on with the malware topic, Didier Stevens released a virustotal-search program. The program will search for VirusTotal reports using a file’s hash (MD5, SHA1, SHA256) and produces a csv file showing the results. One cool thing about the program is it only performs hash searches against Virustotal so a file never gets uploaded. I see numerous uses for this program since it accepts a file containing a list of hashes as input. One way I’m going to start using virustotal-search is for malware detection. One area I tend to look at for malware and exploits are temporary folders in user profiles. It wouldn’t take too much to search those folders looking for any files with an executable, Java archive, or PDF file signatures. Then for each file found perform a search on the file’s hash to determine if VirusTotal detects it as malicious. Best of all, this entire process could be automated and run in the background as you perform your examination.
Malware Strings
Rounding out my linkz about malware related tools comes from the Hexacorn blog. Adam released Hexdrive version 0.3. In Adam’s own words the concept behind Hexdrive is to “extract a subset of all strings from a given file/sample in order to reduce time needed for finding ‘juicy’ stuff – meaning: any string that can be associated with a) malware b) any other category”. Using Hexdrive makes reviewing strings so much easier. You can think of it as applying a filter across the strings to initially see only the relevant ones typically associated with malware. Then afterwards all of the strings can be viewed using something like Bintext or Strings. It’s a nice data reduction technique and is now my first go to tool when looking at strings in a suspected malicious file.
Log2timeline Updates
Log2timeline has been updated a few times since I last spoke about it on the blog. The latest release is version 0.64. There have been quite a few updates ranging from small bug fixes to new input modules to changing the output of some modules. To see all the updates check out the changelog.
Most of the time when I see people reference log2timeline they are creating timelines using either the default module lists (such as winxp) or log2timeline-sift. Everyone does things differently and there is nothing wrong with these approaches. Personally, both approaches doesn’t exactly meet my needs. The majority of the systems I encounter have numerous user profiles stored on them which mean these profiles contain files with timestamps log2timeline extracts. Running a default module list (such as winxp) or log2timeline-sift against the all the user profiles is an issue for me. Why should I include timeline data for all user accounts instead of the one or two user profiles of interest? Why include the internet history for 10 accounts when I only care about one user? Not only does it take additional time for timeline creation but it results in a lot more data then what I need thus slowing down my analysis. I take a different approach; an approach that better meets my needs for all types of cases.
I narrow my focus down to specific user accounts. I either confirm who the person of interest is which tells me what user profiles to examine. Or I check the user profile timestamps to determine which ones to focus on. What exactly does this have to do with log2timeline? The answer lies in the –e switch since it can exclude files or folders. The –e switch can be used to exclude all user profiles I don’t care about. There’s 10 user profiles and I only care about 2 profiles but I only want to run one log2timeline command. No problem if you use the –e switch. To illustrate let’s say I’m looking at the Internet Explorer history on a Windows 7 system with five user profiles: corey, sam, mike, sally b, and alice. I only need to see the browser history for the corey user account but I don’t want to run multiple log2timeline commands. This is where the –e switch comes into play as shown below:
log2timeline.pl -z local -f iehistory -r -e Users\\sam,Users\\mike,"Users\\sally b",Users\\alice,"Users\\All Users" -w timeline.csv C:\
The exclusion switch eliminates anything containing the text used in the switch. I could have used sam instead of Users\\sam but then I might miss some important files such as anything containing the text “sam”. Using a file path limits the amount of data that is skipped but will still eliminate any file or folder that falls within those user profiles (actually anything falling under the C root directory containing the text Users\username). Notice the use of the double back slashes (\\) and the quotes; for the command to work properly this is needed. What’s the command’s end result? The Internet history from every profile stored in the Users folder except for the sam, mike, sally b, alice, and all user profiles is parsed. I know most people don’t run multiple log2timeline commands when generating timelines since they only pick one of the default modules list. Taking the same scenario where I’m only interested in the corey user account on a Windows 7 box check out the command below. This will parse every Windows 7 artifact except for the excluded user profiles (note the command will impact the filesystem metadata for those accounts if the MFT is parsed as well).
log2timeline.pl -z local -f win7 -r -e Users\\sam,Users\\mike,"Users\\sally b",Users\\alice,"Users\\All Users" -w timeline.csv C:\
The end result is a timeline focused only on the user accounts of interest. Personally, I don't use the default module lists in log2timeline but I wanted to show different ways to use the -e switch.
Time and Date Website
Daylight savings time does not occur on the same day each year. One day I was looking around the Internet for a website showing the exact dates when previous daylight savings time changes occurred. I came across the timeanddate.com website. The site has some cool things. There’s a converter to change the date and time from one timezone to another. There’s a timezone map showing where the various timezones are located. A portion of the site even explains what Daylight Savings Time is. The icing on the cake is the world clock where you can select any timezone to get additional information including the historical dates of when Daylight Savings Time occurred. Here is the historical information for the Eastern Timezone for the time period from the year 2000 to 2009. This will be a useful site when you need to make sure that your timestamps are properly taken into consideration Daylight Savings Time.
Jump Lists
The day has finally arrived; over the past few months I’ve been seeing more Windows 7 systems than Windows XP. This means the artifacts available in the Windows 7 operating system are playing a greater role in my cases. One of those artifacts is jump lists and Woanware released a new version of Jumplister which parses them. This new version has the ability to parse out the DestList data and performs a lookup on the AppID.
Process, Process, Process
Despite all the awesome tools people release they won’t be much use if there isn’t a process in place to use them. I could buy the best saws and hammers but they would be worthless to me building a house since I don’t know the process one uses to build a house. I see digital forensics tools in the same light and in hindsight maybe I should have put these links first. Lance is back blogging over at ForensicKB and he posted a draft to the Forensic Process Lifecycle. The lifecycle covers the entire digital forensic process from the Preparation steps to triage to imaging to analysis to report writing. I think this one is a gem and it’s great to see others outlining a digital forensic process to follow. If you live under a rock then this next link may be a surprise but a few months back SANS released their Digital Forensics and Incident Response poster. The poster has two sides; one outlines various Windows artifacts while the other outlines the SANs process to find malware. The artifact side is great and makes a good reference hanging on the wall. However, I really liked seeing and reading about the SANs malware detection process since I’ve never had the opportunity to attend their courses or read their training materials. I highly recommend for anyone to get a copy of the poster (paper and/or electronic versions). I’ve been slacking updating my methodology page but over the weekend I updated a few things. The most obvious is adding links to my relevant blog posts. The other change and maybe less obvious is I moved around some examination steps so they are more efficient for malware cases. The steps reflect the fastest process I’ve found yet to not only find malware on a system but to determine how malware got there. Just an FYI, the methodology is not only limited to malware cases since I use the same process for fraud and acceptable use policy violations.
Sunday, November 20, 2011
Posted by
Corey Harrell
There are different ways to spread malware. Email, instant messaging, removable media, or websites are just a few options leveraged to infect systems. One challenge when performing an examination is determining how the malware ended up on the system which is also referred to as identifying the malware’s initial infection vector (IIV). A few obstacles in determining the IIV is that a system changes over time: files are deleted, programs are installed, temporary folders are emptied, browser history is cleared, or an antivirus program cleaned the system. Every one of those obstacles may hinder the examination. However, they don’t necessary result in not being able to narrow down the IIV since some artifacts may still be present on the system pointing to the how.
There are various reasons provided why an examination isn’t performed on a malware infected system to locate the IIV. I first wanted to point out why taking the time to find the IIV is beneficial instead of focusing on the reasons why people don’t. The purpose of the root cause analysis is to identify the factors lead up to the infection and what actions need to be changed to prevent the reoccurrence of a similar incident. If the infected system is just cleaned and put back into production then how can security controls be adjusted or implemented to reduce malware infecting systems in a similar manner? Let’s see how this works by skipping the root cause analysis and placing blame on a user opening a SPAM email. A new security awareness initiative educates employees on not opening SPAM email which does very little if the malware was a result of a break down in the patch management process. Skipping figuring out the IIV is not only a lost opportunity for security improvements but it prevents knowing when the infection first occurred and what data may have been exposed. This applies to both organizations and individuals.
Determining how the malware infected a system is a challenge but that's not a good enough reason to not try. It may be easier to say it can’t be done, takes too much resources or it's not worth it since someone (aka users) never listen and did something they weren’t suppose to. As a learning opportunity I’m sharing how I identified the initial infection vector in a recent examination by showing my thought process and tool usage.
First things first… I maintain the utmost confidentiality in any work I perform whether if it’s DFIR or vulnerability assessments. At times on my blog I write detailed posts about actual examinations I performed and every time I’ve requested permission to do so. This post is no different. I was told I can share the information for the greater good since it may help educate others in the DFIR community who are facing malware infected systems.
Background Information
People don’t treat me as their resident “IT guy” to fix their computer issues anymore. They now usually contact me for another reason because they are aware that I’ve been cleaning infected computers for the past year free of charge. So it’s not a strange occurrence when someone contacts me saying their friend/colleague/family member/etc appears to be infected with a virus and needs a little help. That’s pretty much how this examination came about and I wasn’t provided with any other information except for two requests:
* Tell them how the infection occurred so they can avoid this from happening again
* Remove the viruses from the computer
Investigation Plan
The methodology used throughout the examination is documented on the jIIr Methodology Page. I separated the various system examination steps into the first three areas listed below.
1. Verify the system is infected
2. Locate all malware present on the system
3. Identify the IIV
4. Eradicate the malware and reset any system changes
I organized the areas so each one will build on the previous one. My initial activities were to verify that the system was actually infected as opposed to the requester interpreting a computer issue as an infection. To accomplish this I needed to locate a piece of malware on the system either through antivirus scanning or reviewing the system auto-run locations. If malware was present then the next thing I had to do was locate and document every piece of malware on the computer by: obtaining general information about the system, identifying files created around the time frame malware appeared, and reviewing the programs that executed on the system. The examination would require since the technique excels at highlighting malware on a system. The third area and the focus of this post was to identify the initial infection vector. The IIV is detected by looking at the system activity in the timeline around the timeframe when each piece of malware was dropped onto the system. The activity can reveal if all of the malware is from the same attack or if there were numerous attacks resulting in different malware getting dropped onto the system. The final area is to eradicate every malware identified.
Note: Some activities were conducted in parallel to save time. To make it easier for people to follow my examination I identified each activity with the symbol <Step #>, the commands I ran are in bold, and registry and file paths are italicized.
Verifying the Infection
The computer’s hard drive was connected to my workstation and a software write blocker prevented the drive from being modified. I first reviewed the master boot record (MBR) to see the drive configuration I was dealing with and to check for signs of MBR malware <Step 1>. I ran the Sleuthkit command: mmls.exe -B \\.\PHYSICALDRIVE1 (the -B switch shows the size in bytes). There was nothing odd about the hard drive configuration and I found out that additional time was needed to complete the examination since I was dealing with a 500 GB hard drive. To assist with identifying known malware on the system I fired off a Kaspersky antivirus scan against the drive <Step 2>.
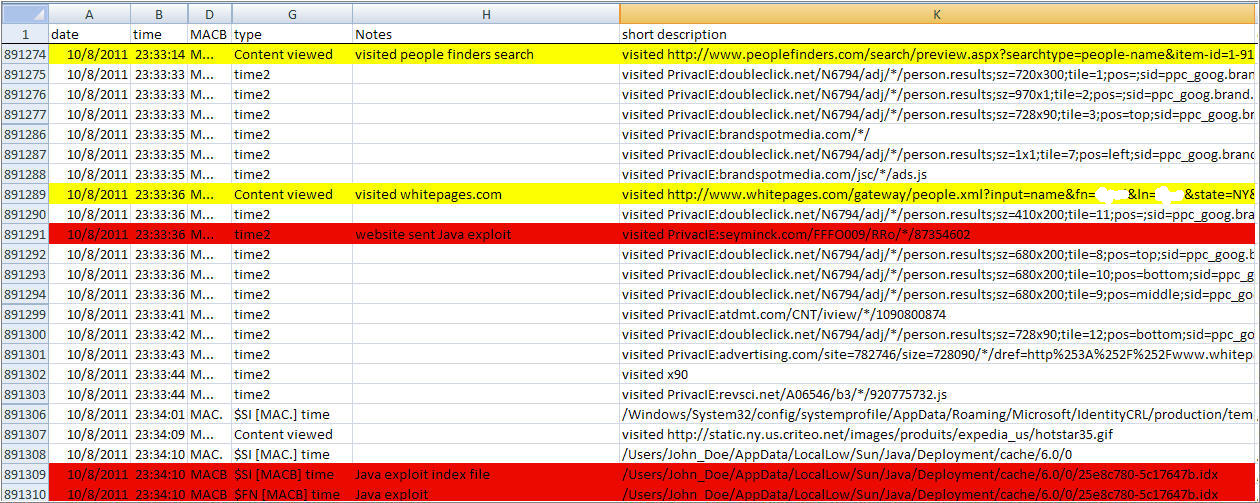
Knowing the antivirus scan was going to take forever to complete I moved on to checking out the system’s auto-runs locations for any signs of infection. The Sysinternals AutoRuns for Windows utility was executed against the Windows folder and the only user profile on the system <Step 3>. In the auto-runs I was looking for unusual paths launching executables, misspelled file names, and unusual folders/files. It wasn’t long before I came across an executable with a random name in the HKCU\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon\Shell registry key.
The HKCU\Software\Microsoft\Windows\CurrentVersion\Run registry key also listed under Auto-runs Logon tab showed that the C:\Users\John_Doe\AppData\Roaming folder had more than just one randomly named executable. The key also showed an additional location which was the C:\Users\John_Doe\AppData\Roaming\Microsoft folder.